Viqsi
"that chick from Ohio"
I'll stick with Puckpedia for the time being simply because it's accurate, even if it is sometimes a pain to navigate. I'm more willing to deal with annoying interfaces than being misled.

The only folks who are going to understand this are fellow web geeks and developers, and virtually nobody's going to care about this other than me (and even that's limited), but I needed to rant somewhere.
If you've ever tried to make use of a browser's ability to add new sites' searches to their built-in search options, y'all may have noticed that CapWages' search doesn't work like that - along with several other hockey-related sites, but whatever. I tend to consider that to be a challenge that I've addressed before (you can see my horrible hacks here if you're morbidly curious) and needed a palette-cleanser from some work annoyances, so I decided to give making that work with CapWages a try. Surely it'd be a quick and easy win, right?
No. So very no. OMFG these people are blisteringly incompetent to a fault or being downright infuriating in their obfuscation attempts or both. Sure, they're following that same infuriating trend of making the client grab a Giant-Ass JSON Object Array Of Players and search it client-side, but I worked around that years ago with Sports Forecaster; that's old hat. But these pigf***ers don't even have a API endpoint to retrieve that list; they just have a giant-ass string hardcoded into their app bundle that gets on-the-fly JSON.parse()d and then Unicode normalized (because they store this string, not in UTF-8, but in WINDOWS-125f***ing2! IN 2024!). So you get to forcibly extract that string from Javascript code yourself (break out the regexes!). Only since it's part of a webpack bundle, our target naturally has a version hash embedded in its filename, so you'd have to do multiple fetch()es to first get their front page and then extract the filename for that part of the bundle and then fetch that file and then extract that Giant-Ass String and then JSON.parse() it yourself and then do your client-side search and...
...yeah, I went back to paying work and I'll consider coming back to this some other time. It's a solvable problem, but so is stabbing people.
So, yeah, now I have an additional reason to not be happy with CapWages and just stick to PuckPedia, which still at least does its actual search logic server-side (even tho it still returns JSON so I still have to parse the results to something navigable myself...).
Well that’s a big pain in the but, also cap wages has some errors, you notice once in awhile, but I’m sure they fix them once awareThe only folks who are going to understand this are fellow web geeks and developers, and virtually nobody's going to care about this other than me (and even that's limited), but I needed to rant somewhere.
If you've ever tried to make use of a browser's ability to add new sites' searches to their built-in search options, y'all may have noticed that CapWages' search doesn't work like that - along with several other hockey-related sites, but whatever. I tend to consider that to be a challenge that I've addressed before (you can see my horrible hacks here if you're morbidly curious) and needed a palette-cleanser from some work annoyances, so I decided to give making that work with CapWages a try. Surely it'd be a quick and easy win, right?
No. So very no. OMFG these people are blisteringly incompetent to a fault or being downright infuriating in their obfuscation attempts or both. Sure, they're following that same infuriating trend of making the client grab a Giant-Ass JSON Object Array Of Players and search it client-side, but I worked around that years ago with Sports Forecaster; that's old hat. But these pigf***ers don't even have a API endpoint to retrieve that list; they just have a giant-ass string hardcoded into their app bundle that gets on-the-fly JSON.parse()d and then Unicode normalized (because they store this string, not in UTF-8, but in WINDOWS-125f***ing2! IN 2024!). So you get to forcibly extract that string from Javascript code yourself (break out the regexes!). Only since it's part of a webpack bundle, our target naturally has a version hash embedded in its filename, so you'd have to do multiple fetch()es to first get their front page and then extract the filename for that part of the bundle and then fetch that file and then extract that Giant-Ass String and then JSON.parse() it yourself and then do your client-side search and...
...yeah, I went back to paying work and I'll consider coming back to this some other time. It's a solvable problem, but so is stabbing people.
So, yeah, now I have an additional reason to not be happy with CapWages and just stick to PuckPedia, which still at least does its actual search logic server-side (even tho it still returns JSON so I still have to parse the results to something navigable myself...).
Huh. Normally when I go on a frothing rant like that I don't expect anybody on the other end to actually be listening.Hi everyone. Thanks for your feedback! I run CapWages and so I wanted to quickly answer a couple of questions:
1. You should be able to see the trade summary on the player details pages, but you're right it's not linking to the actual trade. We'll work on that!
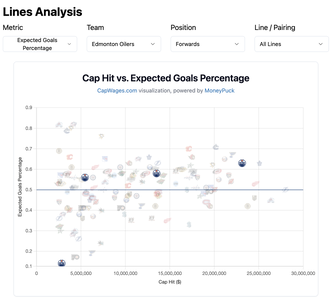
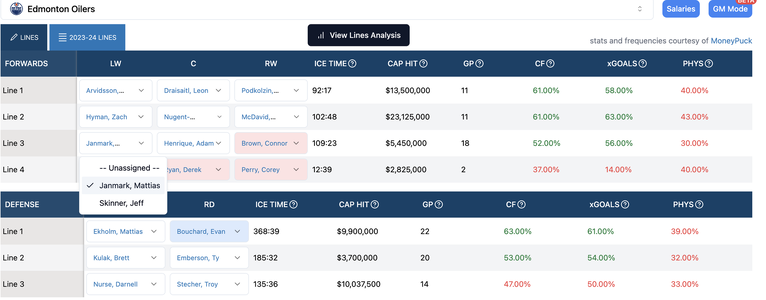
2. Our depth charts are a bit different than the ones on - say - Daily Faceoff or PP. What they show are the projected lineups for the next game. Which is great for betting or fantasy, but doesn't give you a great idea of how players have typically been deployed and how they're performing. We show the most frequently deployed lines (and their associated stats). It's also a bit more interactive (so you can see what those lines look like as you switch players in and out)
We are (slowly) working on showing daily projected lineups as well, though.
3. Why does search happen client-side? tldr: because we chose not to have ads. Client-side searching helps us keep infrastructure costs down so we can absorb them without having to pollute the side with ads. But good news! We've introduced a subscription model, and - if this is something folks are interested in - we're happy to introduce an API that will allow programatic access to our data.
Cheers!
P.S. Feel free to reach out with more ideas/suggestions/etc
 Mea culpa.
Mea culpa.") ) but if there's Nicer Ways that require less poking at y'all's server, that would certainly be preferable. (OTOH, if it's more trouble than it's worth at this point, that's probably fair; I'm just grumpy. )
) but if there's Nicer Ways that require less poking at y'all's server, that would certainly be preferable. (OTOH, if it's more trouble than it's worth at this point, that's probably fair; I'm just grumpy. )